
Not All Document AI Is Created Equal
Most platforms extract text. Redshred extracts intelligence.
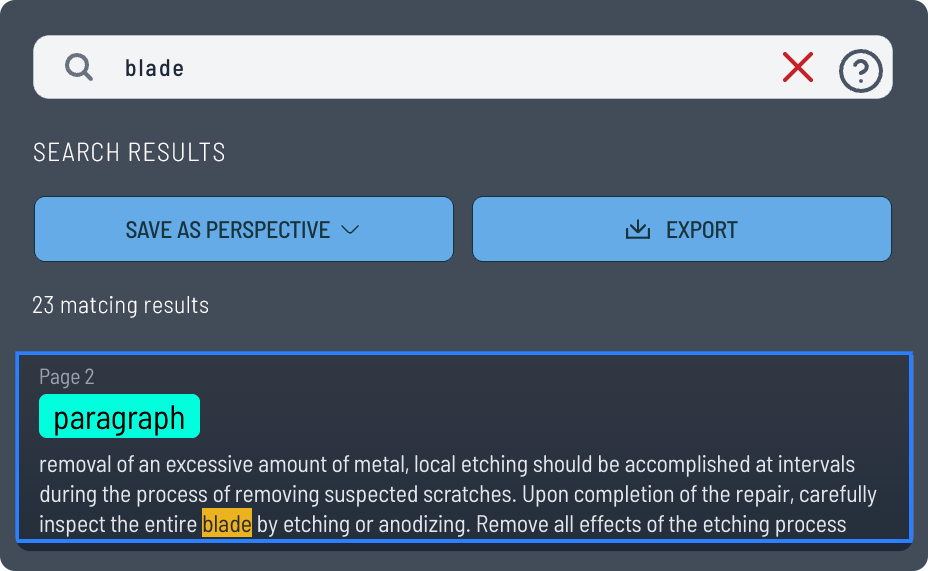


















Structured databases that power faster decisions, better training, and smarter operations.

Ingest
Convert technical documents into structured databases

Extract
Pull critical content with targeted AI precision

Enrich
Layer metadata for intelligent search and retrieval

Extend
Integrate with downstream applications via API

Empower
Feed LLMs better data for superior outcomes

Iterate
Cache and reuse outputs to maximize efficiency
Built for Every Technical Workflow

Field Service & Mobile
Deliver precise technical guidance to technicians in the field—tablet-ready, offline-capable, with real-time procedural updates.

AR/VR Training
Transform static manuals into immersive training experiences. Hardware-agnostic integration for any AR/VR platform.

Digital Twins
Link technical documentation to 3D models and IoT data—creating living documentation that evolves with your assets.

Cross-Reference Linking
Automatically connect related information across thousands of documents—finding dependencies other systems miss.

Supply Chain Intelligence
Extract and normalize parts data, specifications, and supplier information from unstructured technical documentation.

AI-Ready Infrastructure
Structured metadata and content segmentation make your technical data instantly queryable by LLMs—without hallucinations.
Trusted By Defense & Enterprise
Proven Across Critical Operations






Industries We Serve
Built for Complex Technical Operations







Automotive & Heavy Equipment
Service manuals, parts catalogs, diagnostic procedures. Enable dealer networks and field technicians with structured technical knowledge.


Cybersecurity & Intelligence
Extract architectural intelligence from technical documentation. Vulnerability analysis, threat modeling, system architecture mapping.


Industrial & Manufacturing
Assembly instructions, equipment manuals, quality procedures. Transform shop floor documentation into digital work instructions.

Industries We Serve
Built for Complex Technical Operations
Defense & Aerospace
Aircraft maintenance, battle damage repair, naval aviation systems. Process technical orders, IETM manuals, and engineering drawings at scale.
UAS & Drone Systems
Maintenance documentation for Group 2/3 drones, field repair guides, counter-UAS systems. Support rapid deployment teams with instant technical access.
Maritime & Naval
Ship systems documentation, submarine maintenance, propulsion systems. Link technical manuals across entire vessel ecosystems.
Automotive & Heavy Equipment
Service manuals, parts catalogs, diagnostic procedures. Enable dealer networks and field technicians with structured technical knowledge.
Cybersecurity & Intelligence
Extract architectural intelligence from technical documentation. Vulnerability analysis, threat modeling, system architecture mapping.
Industrial & Manufacturing
Assembly instructions, equipment manuals, quality procedures. Transform shop floor documentation into digital work instructions.


